jax:optax优化库
发表时间:2024-04-22 14:25:53
文章作者:佚名
浏览次数:
jax有自己的一个示例版优化库optimizers,不过这个库非常的小,都没实现学习率训练计划schedule,当然也可以自己写一个函数,learning_rate_fn(steps),然后作为参数传入optimizers.sgd(step_size=learning_rate_fn)即可。
如果自己写比较麻烦,就可以用optax库。
学习率lr对训练网络非常重要,不能太大,也不能太小,太大了不收敛,太小了收敛速度慢,而且泛化能力变差。
一般在初期设置大一点,便于快速收敛,训练后期设置小一些,用于微调。
batchsize也是一样,不能太大,也不能太小,太小收敛速度慢,太大泛化能力也会变差。
batchsize太大也并不能让训练速度加快,因为速度瓶颈可能是数据读取,也可能是碰到了GPU的功耗墙。一般GPU利用率达到100%后,改变batchsize大小,一个epoch的时间相差无几。比如我的笔记本电脑训练resnet50的时候,batchsize=150和batchsize=32一个epoch时间分别是170秒和190秒,差距并不是很大。
通常,lr/batchsize保持在一个合理范围比较好。以resnet50为例,base_learning_rate=0.1*batch_size / 256.在经验上是一个比较合理的设置。batch_size=32时,base_learning_rate=0.0125.
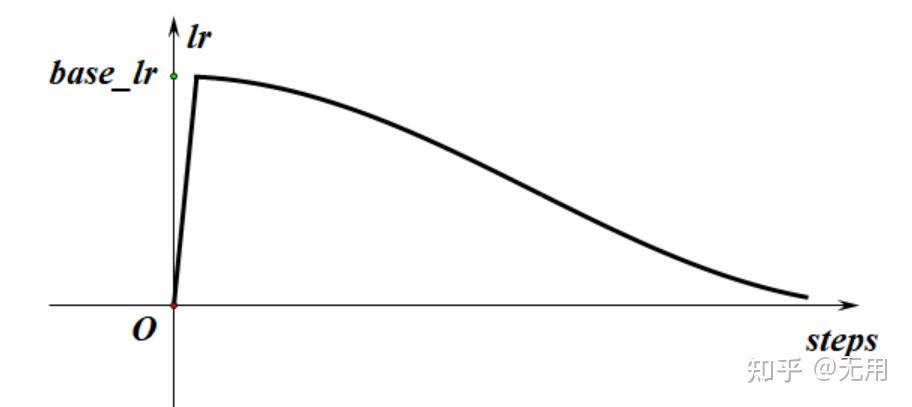
但是,如果一开始就把lr设为0.0125.,有可能直接就爆了,根本收敛不了。所以先用较小的学习率暖暖场,这过程叫warmup,所以学习率大小的走势,大概如下图所示
def create_learning_rate_fn(config,base_learning_rate: float,steps_per_epoch: int):
warmup_fn = optax.linear_schedule(init_value=0., end_value=base_learning_rate,transition_steps=config.warmup_epochs * steps_per_epoch)
cosine_epochs = max(config.num_epochs - config.warmup_epochs, 1)
cosine_fn = optax.cosine_decay_schedule(init_value=base_learning_rate,decay_steps=cosine_epochs * steps_per_epoch)
schedule_fn = optax.join_schedules(schedules=[warmup_fn, cosine_fn],boundaries=[config.warmup_epochs * steps_per_epoch])
return schedule_fn
base_learning_rate = config.learning_rate * config.batch_size / 256.
steps_per_epoch=40000//config.batch_size
learning_rate_fn = create_learning_rate_fn(config, base_learning_rate, steps_per_epoch)
optimizer = optax.sgd(learning_rate=learning_rate_fn,momentum= 0.9)
opt_state = optimizer.init(init_params)
params=init_params@jit
def update(i,params, opt_state, batch):
g,ans=grad(loss_fn,has_aux=True)(params, batch)
updates, opt_state = optimizer.update(g, opt_state)
params = optax.apply_updates(params, updates)
return params,opt_state,ans优化器只是更新权重这个过程,不用库,自己写这个过程也复杂不了很多。比如上面这个带warmup的余弦衰减过程,可以写为
def myschedule(steps):
cosine_epochs = max(config.num_epochs - config.warmup_epochs, 1)
warmup_decay_steps=config.warmup_epochs*steps_per_epoch
cosine_decay_steps=cosine_epochs*steps_per_epoch
return jnp.select([steps<config.warmup_epochs*steps_per_epoch,
steps<config.num_epochs* steps_per_epoch],
[base_learning_rate*steps/warmup_decay_steps,
base_learning_rate*(0.5*jnp.cos(jnp.pi*(steps-warmup_decay_steps)/cosine_decay_steps)+0.5+0.000001)],0.000001)更新过程
@jit
def update(steps,params, updates, batch):
g,ans=grad(loss_fn,has_aux=True)(params, batch)
moments=0.9
lr=myschedule(steps)
updates=jax.tree_util.tree_map(lambda x,y:lr*x+moments*y,g,updates)
params=jax.tree_util.tree_map(lambda x,y: x-y,params,updates)
return params,updates,ans,lr初始化updates
updates=jax.tree_util.tree_map(lambda x:x*0.0,params)五、完整代码
jax_example